我们在做SEO的时候免不了要进行一些分析竞争对手网站的工作,通常做法是搜索一些核心关键词,通过这些核心关键词来判断哪些网站具体有很强的竞争力,以及跟他相比,我们网站的优势和劣势在哪。
这是一个不错的思路,现在的问题是人工去挖掘的话,一方面效率太低,另一方面数据量不会很大,可能会遗漏一些竞争对手。那么有没有办法能既做到速度快,又能挖掘尽可能多的同行竞争对手网站呢?
我们可以使用Linux / Unix下Shell命令来快速挖掘同行网站,Windows下系统建议使用Unix模拟环境cygwin。我们也能使用一些功能强大的UNIX命令来帮助我们提高效率。
一、前期准备工具
1、斗牛系列关键词挖掘工具:百度推广后台、5118、爱站关键词挖掘等,我本次只用爱站关键词挖掘工具挖掘了一小部分词作为演示。
2、Shell:Linux or Unix or Windows系统使用Cygwin、
3、常用Shell命令,请参考《Shell日志分析常用命令快速入门》
二、实现思路
1、用关键词挖掘工具挖掘批一批行业词,比如有1000个词,如下图:
2、把每个词去百度搜索一下,取前50个结果URL,然后汇总所得到的所有URL;
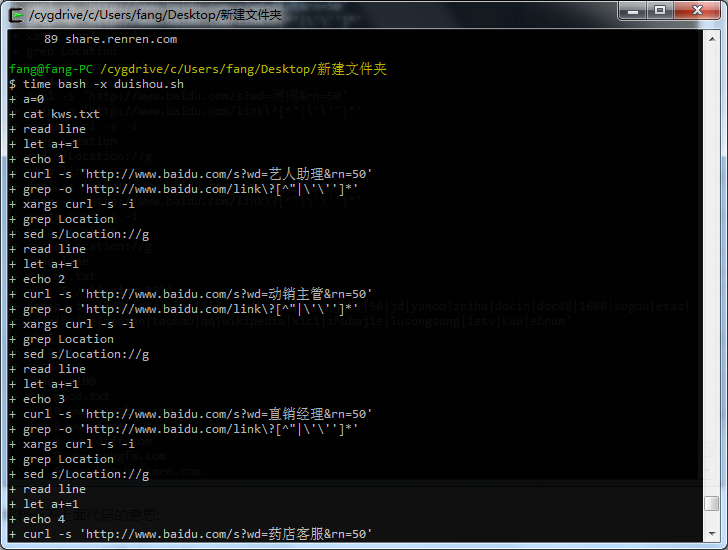
代码如下:第一条命令是转到我们要处理的文件kws.txt所在的目录,第二条命令是运行duishou.sh这个shell批处理文件,并计算耗时。
cd /cygdrive/c/Users/fang/Desktop/新建文件夹
time bash -x duishou.sh
测试跑1000个词试试:
三、程序运行结果
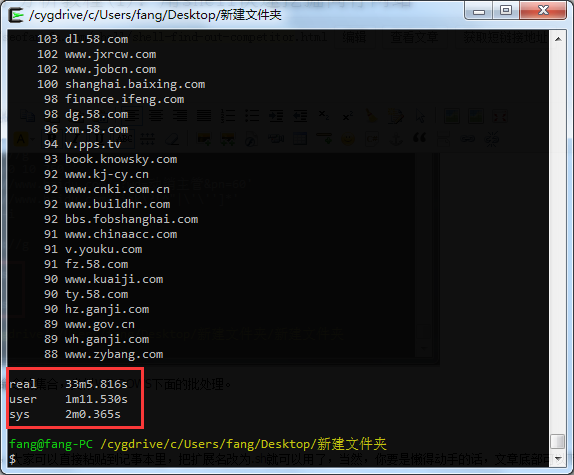
测试跑1000个词,用时33分钟,你觉得效率怎么样?
四、测试效果
URL前面的数字越大,表示该网站的竞争力越强大。
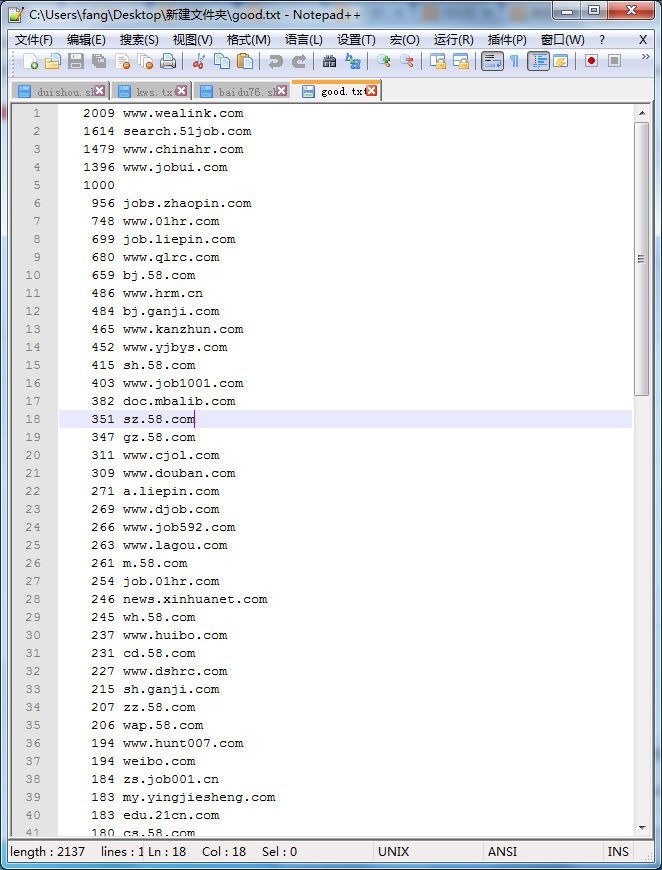
其中duishou.sh是几条命令的集合,类似WINDOWS下面的批处理。
五、程序源代码
1、把以下代码粘贴到记事本,保存成文件名duishou.sh
#!bin/bash
#############作用################
#快速高效找到该行业里SEO做得最强的网站;
#############原理################
#根据一批关键词,批量获取这些关键词的百度搜索结果页前50个结果的URL,再将这些URL排序,统计出现次数,出现次数越多,说明该网站的前50名排名覆盖率越高,也就意味着SEO做得越好;
#############用法################
#1、进入Linux or Unix or Cygwin 的Shell命令行
#2、cd 命令切换到工作目录;
#3、输入time bash -x duishou.sh
#4、等运行完毕,查看结果,结果存在good.txt文件中。
#############注意事项#############
#1、kws.txt:关键词列表,一行一个,UTF-8编码
#2、ok.txt:百度搜索结果页前50个结果的URL集合
#3、good.txt:最终结果存放的文件
#4、关键词越多,结果越准确,所以,第一步你得挖掘足够多、足够精准的行业关键词
#开始获取百度前50名网站的URL......
a=0
cat kws.txt|while read line;do
let a+=1
echo $a
curl -s "http://www.baidu.com/s?wd=$line&rn=50"|grep -o "http://www.baidu.com/link\?[^\"|\']*"|xargs curl -s -i|grep "Location"|sed 's/Location://g'
done >ok.txt
#开始分析竞争对手网站....
cat ok.txt|awk -F "/" '{print $3}'|egrep -iv "360|soso|sina|163.com|baidu|sohu|jb51|56|jd|yahoo|zhihu|docin|doc88|1688|sogou|etao|tianya|baike|zmazon|taobao|qq|wikipedia|xici|zhubajie|lusongsong|letv|ku6|ebrum"|sort|uniq -c|sort -nr|head -n100 >good.txt
#展示最终结果......
cat good.txt2、排除百度自身产品结果,以及新浪博客、SOSO、360搜索、360doc、docin等其他高权重网站;
3、取URL重复次数最多的100个作为主要竞争对手。
上诉代码解释:
1、cat ok.txt:打开ok.txt文件;
2、|:管道命令,表示上一步处理完的文件通过该管道输送到下一个命令;
3、awk -F '/' '{print $3}':取URL的主域部分;
4、egrep -iv "360|soso|sina|163.com|baidu|sohu|jb51|56|jd|yahoo|zhihu|docin|doc88|1688|sogou|etao|tianya|baike|zmazon|taobao|qq|wikipedia|xici|zhubajie|lusongsong|letv|ku6|ebrum":排除这些高权重平台的结果;
5、sort:将结果排序,以便进行下一步结果去重并计算重复次数;
6、uniq -c:对结果进步去重并计算重复次数;
7、sort -nr:将重复次数按从大到小排序;
8、head -n100:取原始结果的前100个条数据;
9、>good.txt:将最终结果输出到good.txt中。
如有任何问题或者想法,欢迎交流!
